
Some time ago, Tesla announced that it would build its own supercomputer for machine learning of the Full Self Driving functionality. This now appears to go live from Monday, as Tim Zaman, Engineering Manager for AI Infrastructure at Tesla and Twitter/X announced in a tweet.
The details are interesting. The system consists of 10,000 pieces of H100 processors from NVIDIA, each of which costs $30,000. The cost of this supercomputer is thus around 300 million and are installed on premise at Tesla.
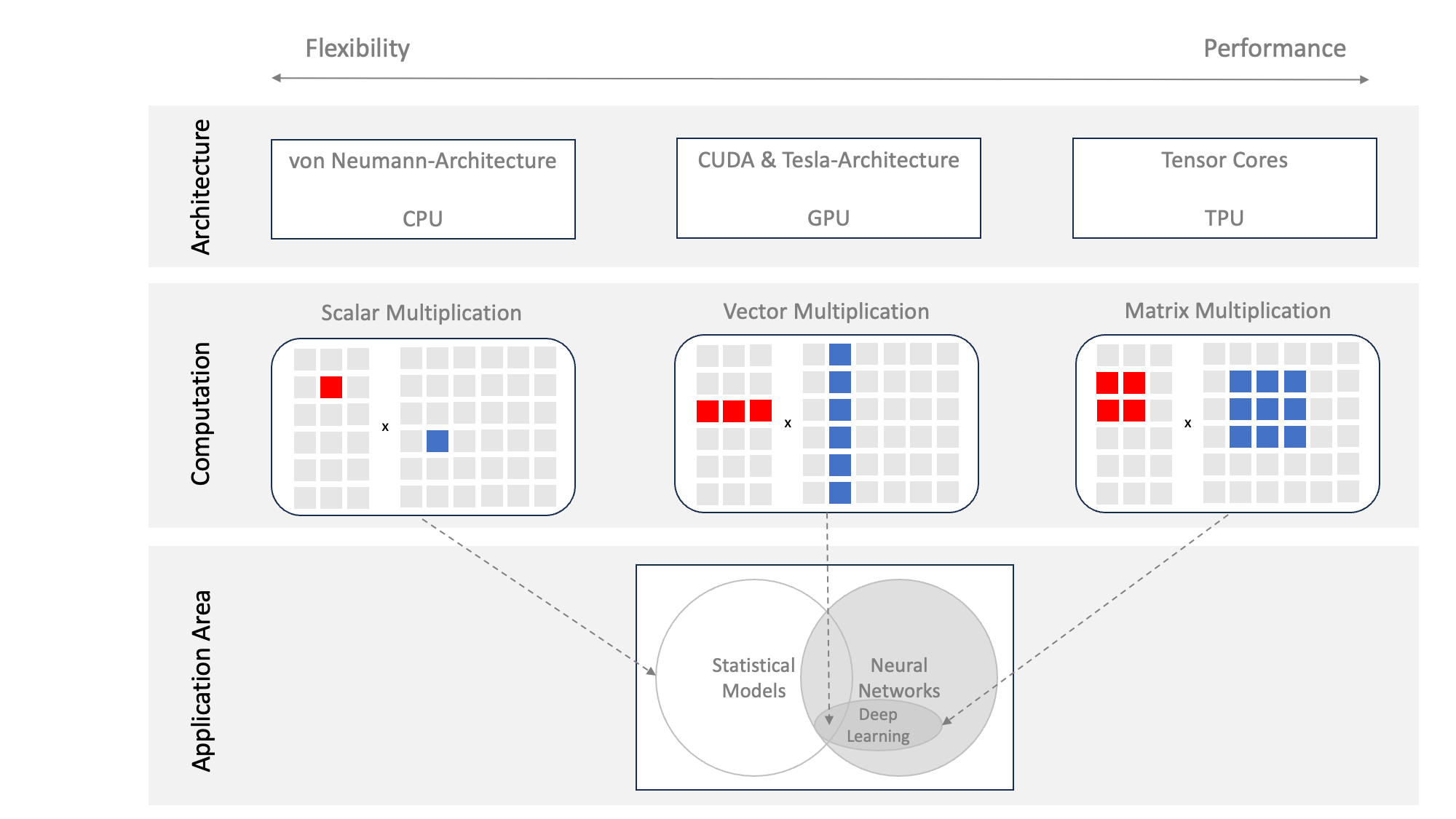
The chips themselves are Tensor GPUs, abbreviated TPUs, which are specifically suited for massive parallel matrix computations used in machine learning systems. Generative pre-trained transformers (GPTs) are also trained on GPU or TPU clusters.
With the supercomputer, Tesla can analyze video data from 5 million vehicles delivered to customers and further develop the FSD. The direct cache alone is 200 petabytes. Tesla owners can authorize Tesla to access their video data by setting the appropriate preferences. According to older evaluations, at least four gigabytes of data have been sent to Tesla per month for years. Tesla now accesses this video data for the FSD supercomputer.
With the TPU cluster, Tesla now hopes to bring the FSD 12 to the point where Level 4 autonomous driving will also be possible. However, the choice of NVIDIA H100 processors seems to be a departure from the original plans to use Tesla’s proprietary Dojo D1 processor for the cluster. Whether this has to do with production difficulties or other reasons is unknown.
This article was also published in German.

4 Comments